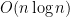Thank God for giving me a learning experience today.
Today, I participated in Codeforces Round #918, which was a Division 4 round. I am currently rated under 1400, which means that the round is rated for me. Instead of posting in a crappy Overleaf document that no one (not even myself) looks at, I will post them somewhere more meaningful (ex. this blog, maybe even AoPS blog, we’ll see).
I woke up slightly before 9:30 am and pulled out my computer just in time for the round to start. Unfortunately, both the main website and m1 were bugged out, which eliminated any possibility for a sub-minute solution for problem A. When the website did eventually load, I typed out what I later realized to be a wrong solution and submitted it. Because the queue was long, I didn’t know about my incorrect submission until ten minutes after my initial submission.
Problem B was straightforward implementation. I was careful to not get integer overflow or any weird verdict for Problem C because the sums dealt with long longs. Thus, I implemented a binary search to compute the square root, which was strictly unnecessary because numbers were only up to 2e14 (with which we can use normal overloaded sqrt() in C++). D was quite nice. I drew out a couple of test cases to realize the quirkiness of the syllables: the strings “CVC” and “CV” end with different types of letters (one a consonant, and one a vowel), so why not implement a greedy solution that iterates backward? The additional constraint specifying that at least one solution exists verified my solution.
Then I looked at problem E and problem F.
I didn’t even bother with G because it mentioned “shortest path”, which meant either implementing a BFS or Dijkstra’s, neither of which I was familiar with.
The first thing that came up to mind for E was an iterative prefix sums algorithm. I knew I had seen somewhere a solution where you compare the current prefix sum with a previous prefix sum in a set. However, I was stuck in the quirkiness of the “even” and “odd” subarrays and thought I had to compute separate prefix arrays for each of them. I drew a couple of test cases and still didn’t get anything.
I skipped to F. I immediately noted the observation that for a person 

I wasted an hour and a half trying to look for a solution trying to optimize the searching time of finding the 
With my mind cleared, I looked at F and decided to approach the problem in a slightly different way. We have the following condition, and the 


I also realized later that E and F are reformulations of basic concepts in programming. A rearrangement of the condition in E yields the problem of finding a contiguous subarray with sum zero, which can be solved with prefix sums. If we rephrase F, the problem is equivalent to finding the number of inversions of an array. For instance, if we denote the intervals using letters, the string ABABCC will have one inversion, when B passes A.
I ran out of time to do G, which was a graph problem.
Overall: 6/7, not bad. Best Div.4 performance so far. I should have taken more time on A to reduce penalty points, but I’m happy that I overcame a mental barrier and solved E/F.
Hopefully, when my fundamental algorithmic problem-solving techniques are polished up, I can go on and learn more advanced techniques needed for USACO Gold/Platinum problems. For now, I’ll first need to pass Bronze. Then Silver.
One step at a time. One concept at a time. One problem at a time.
EDIT 12/29/2023: It turned out that I failed system tests for problem F. I didn’t know that the erase function in the vector class was